在繼續討論如何建造一個機器學習解決方案之前,我們要先來討論這個模型要放在什麼樣的系統之中,接下來三天的時間,將從上而下的了解一個 Fintech 系統會有哪些元件,並以 DS 的角度去思考如何在這樣的系統下提供 Solution
如果你今天建造了一個網路銀行的系統,只有幾百幾千人用戶,不太會遇到效能上的瓶頸,但如果今天是個好幾十萬百萬人用的系統,大量的請求勢必會讓 API 執行速度變慢,而這樣的延遲可能會讓想要提款的用戶抓狂!
試想有一個資料科學家,為了要研究一個特徵是否顯著,寫了一個充滿 JOIN GROUP BY, Sub Query 和 RANKING 的 SQL Command,一次查詢的執行時間就需要耗費好幾十分鐘,而 Query 期間所有的表都會被 Lock,而這個 Lock 很有可能就會導致 API 響應時間變長,最終導致用戶抓狂,所以第一個"我們將資料存儲分成 OLAP 和 OLTP 兩個類別,T 表示 Transaction,A 表示 Analytics",來區分不同起用用圖,我們用以下的圖來解釋: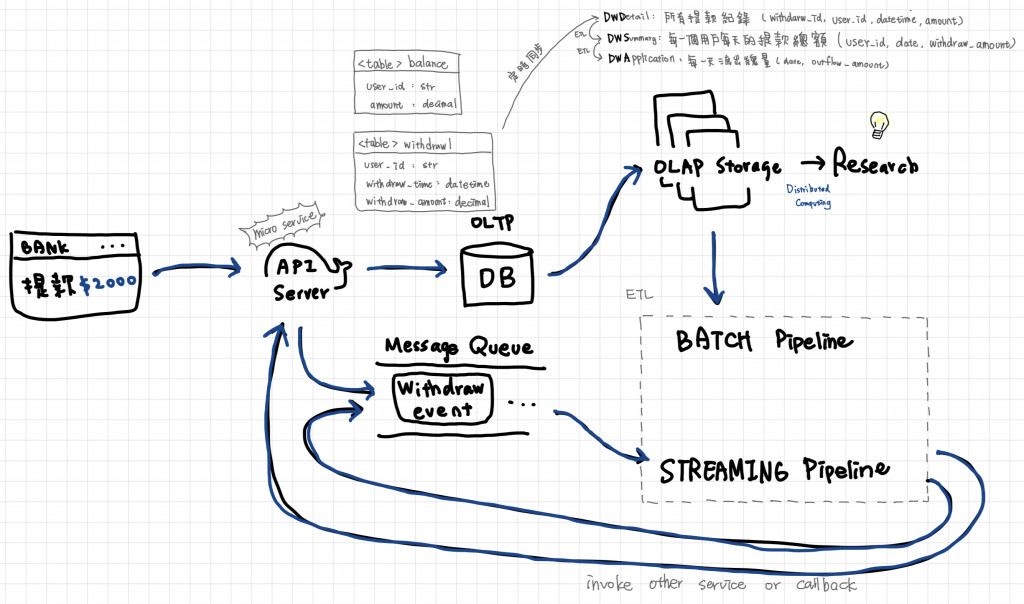
當有一個從 APP 端發出提款的請求時,APP 端就會對資料庫中的兩個資料表進行讀好的操做
到目前為止,就是一個常見的 Web Application 設計,這個資料庫可以是任何雲服務資料庫如 AWS RDs 或自己架的 SQL等等,這些 DB 通常都會有一定程度的 Read/ Write Lock,目的是為了預防 Data Race 等現象發生,舉例來說,有個充滿 QA 性格的用戶,可能會嘗試在短時間內狂提款,如果其中一筆提款發生的當下,因為資料庫還來不及扣掉上一筆提款,導致用戶超額提款,就會造成一定損失,有了這些 Lock 就可以確保上一筆的資料已經更新好了。
但這樣的 Lock 也會造成其他用戶的提款需求被耽誤,更不用說這時候要是還有一批資料科學家和分析師都在的取這資料庫的內容,常常會在這種大型系統設計架構中看到不同的 Paritioning 和 Sharding 來解決 API 請求延遲的問題,但這解決方法主要是解決用戶請求延遲的問題,對於解決資料團隊的問題,一種常見設計就是把資料應用場景拆分為 OLTP 以及 OLAP,其中 OLTP 可以想像成就是原本的資料庫跟 API 系統,而 OLAP 則是把 OLTP 的資料同步備份一份到另一個儲存空間來做使用
OLAP 可以是另外一個 MySQL Database 或是任何儲存空間,比較常見的是使用 Amazon S3 搭配 Hadoop/ Spark 生態系的運算系統, 通常這裡的需求有以下特性
同步的方法常常會見到透過 Message Queue 在消息寫入 OLTP 時同步寫入 OLAP 之中,也有整批資料定時同步的方式,在同步的過程中,常常會加入一些 ETL Pipeline 來將同步的資料做分層,從上面的例子中,最原始的資料有用戶資產以及資金流動表,我們舉資金流動表為例,一個 ETL Pipeline 依照處理層級簡單到複雜 (或說從原始到抽象),依序為:
可以看出上面像是一個 Funnel 依樣一層層的聚合下來,有時候會用 DatawareHouse 分層的概念來設計這個 Funnel 今天的最後我們來介紹今天提到的幾個系統架構元件:
構建一個大型系統以滿足高 QPS 和大量用戶的需求是一個複雜的過程。通過理解和合理分配 OLTP 和 OLAP 的任務,並且有效利用 Message Queue、API、Pipeline 和 Storage 等工具和概念,可以創建一個可靠、可擴展和高效的系統。這樣的設計不僅確保了業務的順利運作,還為數據分析和洞察提供了強大的支援
最後分享一個心得,在做這樣系統設計的時候,要把設計理念, 使用工具和程式碼分開,我覺得一個提供解決方案的好流程是先去了解各個工具他們背後有什麼樣的設計理念,然後再去思考你的設計理念是什麼,每個理念背後都有一個或多個想要解決的問題,最後才去選你的工具,如果一開始就綁定一個工具,在不知道某項功能背後目的情況下直接使用一個工具常常會錯誤的使用而堆疊技術債,屆時還需要花不少時間去設計 Anti-Pattern 來彌補

